


vGate ASR音声認識システム
フュートレックの音声認識システム「vGate ASR」は、騒音環境に強く高精度で、カスタマイズも可能です。そのため、IoTやAI、ロボット、自動車など次世代技術を用いた製品やサービスに適しています。お客様のご利用環境や用途に応じて、最適な音声認識システムをご提供します。
インターネットに接続して、大語彙の音声認識が可能な「サーバー型音声認識システム」と、機器に組み込んで音声認識を行う「ローカル型音声認識システム」のご提供が可能です。
「サーバー型」と「ローカル型」を切り替えて利用できる「ハイブリッド型」でのご提供も可能です。
サーバー型音声認識システム
音声認識エンジンはサーバーに搭載し、機器とインターネット接続をして音声認識処理を実行します。
大量の語彙を認識することができる高性能な音声認識システムです。
AIを利用した会話システム、自由な発話や豊富な言葉の認識に適しています。
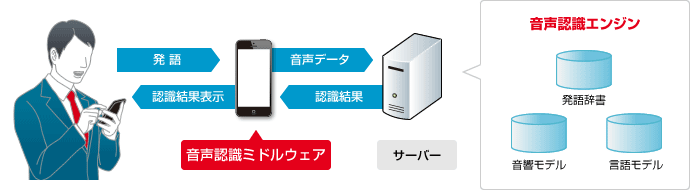
| 音声認識ミドルウェア | ・・・ 音声認識機能の制御を行うミドルウェア |
| 音声認識エンジン | ・・・ 発話辞書・音響モデル・言語モデルをサーバーに持つ |
■特長
大量の語彙・モデルをサーバーに持つことが出来るため、文章の入力など高性能な認識が可能です。
オンプレミス型音声認識システム
お客様がサーバーを自社管理・運用される場合に、お客様の環境内に音声認識のバックエンドサーバーを構築する「オンプレミス型音声認識システム」をご提供します。
お客様の用途や環境にカスタマイズした音声認識システムのご提供が可能です。
また、お客様ご自身で言語モデルや固有名詞などのメンテナンスができる「言語モデル更新サービス」や「単語登録サービス」もご利用いただけます。
vGate ASPサービス
サーバー型音声認識システムを構築する場合に、フュートレックが用意したASPサイトを利用することによって、お客様によるサーバー設備の導入や運用管理等の負担を節減することができます。
ローカル型音声認識システム
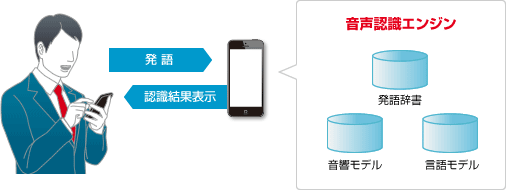
機器内に搭載し、インターネットに接続をせずに音声認識が可能な、ローカル型の音声認識(LSR)システムです。音声データをサーバーに送信する必要がないため、情報の外部流出のリスクを軽減できます。
ローカル型大語彙連続音声認識(L-LVCSR)システム
ローカル型大語彙連続音声認識(L-LVCSR)は、サーバーとの通信を行わないローカル型音声認識(LSR)でありながら、連続した文章の認識が可能です。
機器内に搭載されたモデルのみで音声認識を行うので、認識できる語彙数などはサーバー型の音声認識より少なくなりますが、通信せずに音声認識ができる、ということが、情報保護という視点では「安心・安全」につながります。
従来のローカル型音声認識(LSR)は、「左」「右」「はい」「いいえ」などの単語認識が中心のコマンド入力に対応したものが一般的でしたが、フュートレックの処理量削減技術などにより、ローカルでありながら ニューラルネットワーク構造の高性能音声認識システムを実現しました。
フュートレックのローカル型大語彙連続音声認識(L-LVCSR)は、連続した文章に対応できるため、搭載できる製品の用途が広がります。
■特長
-
インターネット接続が不要
インターネット接続が不要で、利用場所の通信環境に依存せず認識が可能です。 -
お客様情報を安全に保護
音声データをサーバーに送る必要がないため、情報の外部流出のリスクを軽減できます。 -
レスポンスが早い
ネットワークの遅延に影響されないので、レスポンスが早く、快適に動作します。 -
信頼の開発技術
フュートレックは、ロボットや車載など、ローカル型の音声認識に多数の実績があり、搭載端末のCPUに合わせて最適な音声認識エンジンを提供します。
特に、ローカル型大語彙連続音声認識(L-LVCSR)システムでは、音響モデル、言語モデル、音声認識エンジンのそれぞれの処理量削減技術により、高精度音声認識を提供します。
サーバー型音声認識システムの基本仕様
基本仕様
| 対応OS | Android(5.0以上)、iOS(11以上)、Windows(Windows8.1以上)、Linux |
|---|---|
| 対応CPU | x86、x86_64、ARM(Cortex-A9以降) |
| 必要メモリ | RAM:6MB、ROM:7MB |
| 対応OS | Linux(64bit) |
|---|---|
| 対応CPU | Intel Xeon E5 v2 / 2.6GHz 以上推奨 |
| 必要メモリ | 4〜7GB(50〜100万語彙言語モデルの場合) |
| 対応言語 | 日本語、英語、中国語(北京語)、韓国語、タイ語、インドネシア語 |
ローカル型音声認識システムの基本仕様
基本仕様
音声認識ミドルウエア
■ローカル型音声認識システム(定型文・単語・コマンド入力向け)
機器内データなど数十〜数万程度の語彙・モデルによる定型文・単語・コマンド入力に最適
| 対応OS | Android(5.0以上)、iOS(11以上)、Windows(Windows8.1以上)、Linux |
|---|---|
| 対応CPU | x86、x86_64、ARM(Cortex-A9以降) |
| 必要メモリ | RAM:6MB+α、ROM:7MB+α※1 ※1 利用する言語モデルや動作モードによってRAM容量は変動 認識語彙が100程度のGMMモデルの場合:α=RAM:120MB、ROM:3MB 認識語彙が2万程度のDNNモデルの場合:α=RAM:200MB、ROM:40MB |
■ローカル型大語彙連続音声認識(L-LVCSR)システム(会話や文章入力向け)
会話や一般的な文章などを、区切らずに連続して音声認識する場合に有効。
フュートレックの処理量削減技術について
サーバー型音声認識と同等のモデルやエンジンから処理量削減技術により、搭載端末での動作を可能にしています。
- 音響モデル:サーバー型音声認識と同等の音声学習量で、ニューラルネットワークの構造を搭載端末のCPUで動作可能なレベルに縮小。
- 言語モデル:サーバー型音声認識の大語彙モデルを構成しているコーパス群から、ローカルで使用するタスクに合致した最低限のコーパスを使用しモデルを構築。
- 音声認識エンジン:サーバー型音声認識エンジンと同等の技術を導入しながら、搭載端末で動作するようなパラメーターのチューニングを実施。
| 対応OS | Android(5.0以上)、iOS(11以上)、Windows(Windows8.1以上)、Linux |
|---|---|
| 対応CPU | x86、x86_64、ARM(Cortex A57以降) |
| 必要メモリ | RAM:300MB、ROM:200MB |
研究機関の技術をベースとした vGate ASR
フュートレックの音声認識システム vGate ASRは、研究機関の技術をベースに開発した高性能な音声認識エンジンです。
vGate ASR:音声関連技術研究のパイオニアであるATR(株式会社国際電気通信基礎技術研究所)、NICT(国立研究開発法人情報通信研究機構)との、強固なパートナーシップを通じた共同研究及び要素技術を活用しています。
vGate ASR2 powered by SpeechRec:NTTテクノクロス株式会社の高精度音声認識ソフトウェア「SpeechRec」の最新版をベースとして開発した音声認識システムです。
「SpeechRec」には、NTTグループが提供するAI「corevo®」を構成する音声認識技術が搭載されています。
※ corevo®は日本電信電話株式会社の登録商標です。(https://group.ntt/jp/)


